ハイブリッドクラウド象の分割
シンプルかつ記憶しやすい思決定モデルを使えば、エレベーターアーキテクトはより良い決定をより意識的に行うことができます。ハイブリッドクラウドはこのための良いテストケースです。
ハイブリッドマルチクラウドに関する以前の記事で説明したように、ハイブリッドクラウドは、少なくとも一時的な状態としてあらゆる企業のクラウドシナリオにあらわれます。理由は単純です。ある日、全てのワークロードがデータセンターから魔法のようになくなることはありません。いくつかのアプリケーションはすでにクラウドにあり、他のアプリケーションはいまだにオンプレミスにあります。そして、これら二つの場所にデプロイされたアプリケーションは協調して動作する必要があるでしょう。
つまり、ハイブリッドが流行語になるのは当然でしょう。とはいえ、アーキテクチャ思考を適用することには大きなメリットがあります。それでは、前回の定義から始めてみましょう。
ハイブリッドクラウドアーキテクチャはワークロードをクラウドとオンプレミス環境に分割します。一般的に、これらのワークロードは協調して動作します。
きちんとしたクラウドコンピューティング戦略を定義すること自体がすでに十分複雑なので、単純な定義が一番役にたちます。単純な定義はさまざまな人々がコンセプトや決定を理解するのに役立ちます。それだけではなく、どのように作られているかに焦点を当てるかわりに、どのように利用されるのかを強調します(構造ではなく意図に注目するのはパターンの著者の性なのかもしれません)。
残念ながら、定義は最初の一歩にすぎません。定義したものを実現するためには何か具体的なものに発展させる必要があります。そのために、アーキテクトエレベータに乗って数階降りて、重要なニュアンスを理解し、分類してみましょう。
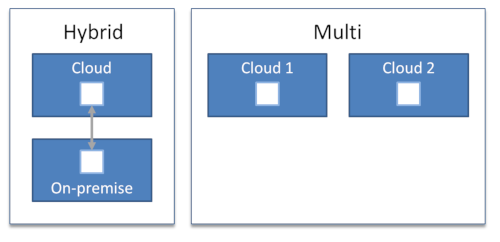
二つに分離された環境はハイブリッドではない
いくつかのワークロードをクラウドにそして残りをオンプレミスに置くのは、残念ながら単に別のコンピューティング環境をポートフォリオに追加しているにすぎません。複雑さを求めるCIOはいません。つまり、これは良い計画ではないように思えます。
複雑さを求めるCIOはいません。クラウドを別のデータセンターにしてはいけません。
したがって、ハイブリッドと呼ぶためには環境全体の統合管理が必要です。ハイブリッドカーの例で考えてみましょう。ハイブリッドカーで難しいのは、バッテリーと電気モーターをガソリン車に組み込むことではありません。二つのシステムをシームレスに調和のとれた方法で機能させることが難しかったのです。これが、トヨタプリウスがハイブリッドカーと呼ばれる理由です。
先ほどの定義を見直しましょう。
ハイブリッドクラウドアーキテクチャはワークロードをクラウドとオンプレミス環境に分割します。一般的に、これらのワークロードは協調して動作します。両方の環境は統合管理されます。
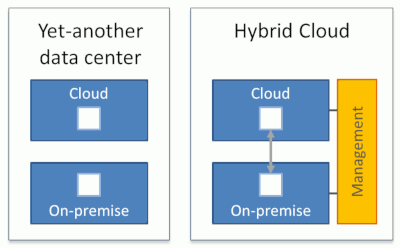
さまざまな環境の統合管理は簡単ではありませんが、いくつか方法があります。
- オンプレミス上にクラウド環境に類似したものを構築する。例えば、AWS OutpostsやAzure Stackを利用します。
- 既存のオンプレミス環境をクラウド上にコピーする。例えば、VMWare Cloudを使います。
- 統合されたランタイムと管理レイヤーを両方の環境に拡張します。例えば、コンテナ、Kubernetes、Google Anthosのような管理レイヤーを使用します。
- クラウド上のデータをオンプレミス環境から簡単に利用できるようにします。例えば、AWS Storage Gateway、あるいはNetApp SnapMirrorのようなストレージレプリケーションソリューションを使います。
- アイデンティティ管理とアクセス管理を統合します。例えば、クラウドアカウントをActive Directoryに統合します。
よく考えてみると、これらの選択の判断は別の記事にするに十分なボリュームです。この記事では、ハイブリッドクラウドの基本的な決定について考えてみましょう。
ハイブリッドの分割 - 31種類の味
ハイブリッドクラウドの重要なアーキテクチャ上の決定事項はワークロードの分割方法です。つまり、ITシステムのどの部分をクラウドに移行し、どの部分をオンプレミスに残すかです。この決定は、ITシステムのつなぎ目を見つけるという考え方に密接に関係しています。Mike Feathersは彼の古典と言えるWorking Effectively with Legacy Code(日本語訳はレガシーコード改善ガイド)の中で(知る限り)はじめてつなぎ目について説明しました。つなぎ目は分割による依存関係があまり増えずに、パフォーマンスの低下のような実行時の問題を引き起こさない場所です。
ワークロードを分割する31の方法を記述することはできないので、興味をひくタイトルをつけたことを謝っておきます。とはいえ、できる限りカタログ化したいと思います。これはいくつかの点で役に立ちます。
- 選択とその理由を簡単に伝えることができるので、共通の語彙は意思決定を透明にします。
- また、このリストを使うことにより選択肢に見落としがないことを確認することもできます。特に法的規制への懸念やデータ保存要件によりクラウドへ移行できない場合は、便利な定石を使いクラウドに移行するための選択肢すべてを検討したことを確認できます。
- 最後に、選択肢を明確にすることにより、各選択肢の適用可能性、長所、短所を矛盾なく検討できます。また、ある選択肢を選択するときに注意すべき点も明確です。
クラウド象の分割方法
企業がハイブリッド環境にまたがってワークロードを分割する方法は少なくとも八つあります。もっと見たことがある人もいるかもしれません。
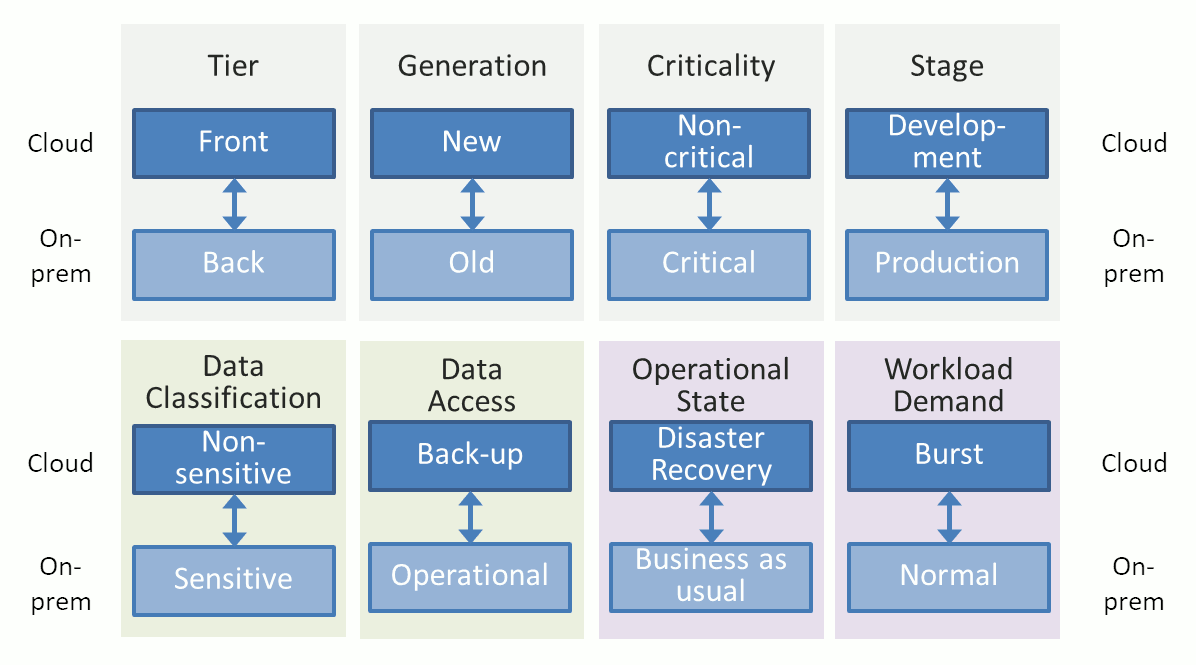
この一覧の主な目的は知られていない選択肢を見つけることではありません。基本的な確認に便利なようによく知られている選択肢を集めたものです。それぞれのアプローチをもう少し詳しく見てみましょう。
層: フロントとバック (Tier: Front vs. Back)
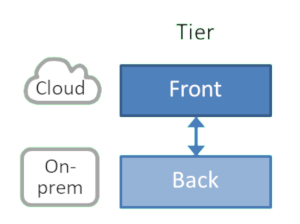
顧客やエコシステムに面しているコンポーネント、別名「フロントエンドシステム」、あるいは「エンゲージメントシステム」をクラウドに移行し、バックエンドシステムを維持するのは一般的な戦略です。
私は2スピードアーキテクチャは好きではありませんが、理由によってはこのアプローチが当然の選択になります。
- フロントエンドコンポーネントはインターネットに公開されているので、インターネットからクラウドにトラフィックを直接ルーティングすることにより、遅延や企業ネットワークのトラフィックの輻輳を減らすことができます。
- 激しくトラフィックが変動しがちなフロントエンドコンポーネントにとって、柔軟なスケーリングは価値があります。
- フロントエンドシステムは最新のツールとアーキテクチャを使用して開発される可能性が高いため、クラウドに適しています。
- 個人を特定可能な情報や機密情報をフロントエンドシステムが保存する可能性が低くなります。これは、データが通常バックエンドに渡されるからです。企業の方針がこのようなデータのクラウドへの保管を禁止している環境では、フロントエンドシステムがクラウドへの移行の候補となります。
これらのわかりやすい利点に加えて、次の注意すべき点を除くと、アーキテクチャはそれほど興味深いものではありません。
- フロントエンドが柔軟なスケーリングの恩恵を受けたとしても、ほとんどのバックエンドはそれに伴う負荷の急激な増加を処理することができません。したがって、キャッシュやキューの利用、計算コストの高い処理のクラウドへの移行ができない場合は、エンドツーエンドのアプリケーションのスケーラビリティを改善できないでしょう。
- 同様にアプリケーションの信頼性に問題がある場合、半分だけをクラウドに移行しても問題は解決しません。
- 多くのフロントエンドはバックエンド、あるいは特にデータベースと「おしゃべり」に通信します。これは、これらのシステムの距離が近い環境向けに構築されているからです。フロントエンドに対する一つのリクエストは数十、時には数百のリクエストをバックエンドに発行します。このようなおしゃべりなチャネルをクラウドとオンプレミスに分割するとエンドユーザは遅延により待たされることが多くなるでしょう。
「2スピードIT」の興奮が消え去ったとしても、このアプローチは依然として優れた移行の中間ステップです。ただし、長期的な戦略と混同してはいけません。
世代: 新しいものと古いもの (Generation: New vs. Old)
密接に関係しているのは、新しいものと古いものによる分割です。すでに説明したように、新しいシステムは一般的にスケーラブル、かつ独立してデプロイできるように設計されているため、クラウドにデプロイするのが自然であることが多いでしょう。また、新しいシステムは比較的小規模で、クラウドネイティブと呼ばれるにふさわしいものです。クラウドネイティブという言葉はクラウドへの移行(移住)を禁じているように見えるので好きではありませんが。
繰り返しになりますが、この分割には理由があります。
- 新しいコンポーネントはマイクロサービス、継続的インテグレーション(CI)、テストとデプロイの自動化のような最新のツールとアーキテクチャを使うことが多いでしょう。したがって、クラウドをうまく活用できます。
- 新しいコンポーネントはコンテナ上で稼働することが多いので、マネージドKubernetesやサーバーレス環境のような高度なレベルのクラウドサービスを利用することができます。
- 新しいコンポーネントはよく理解されテストされていることが多いので、移行リスクが軽減されます。
繰り返しになりますが、考慮すべきこともあります。
- 新しいものと古いものの分割は、既存のシステムのアーキテクチャとうまく一致しないかもしれません。つまり、良いつなぎ目ではないのです。例えば、凝集性の高いコンポーネントをデータセンターの境界を超えて分割すると、パフォーマンスが低下する可能性があります。
- 長い時間をかけて全てのコンポーネントを入れ替えている最中でなければ、この戦略は「全てをクラウド」に移行しません。・
新しいシステムを開発しているのであれば、これは全体としては良いアプローチと言えます。最終的に古いものは新しいものでを置き換えられます。
重要度: 重要でないものと重要なもの (Criticality: Non-critical vs. Critical)
多くの企業は本腰を入れる前につま先を水につけることを好みます。初期の学習曲線と避けがたい失敗を許容できるいくつかの単純なアプリケーションでクラウドを試すでしょう。「早く失敗」し、その過程で学ぶのは理にかなっています。
- スキルセットの取得はクラウド移行の主な阻害要因の一つです。ベンダーのデモほど物事は簡単ではありません。したがって、小規模なものからはじめてすぐにフィードバックを得ることにより、低リスクな環境で必要なスキルを手に入れることができます。
- 小規模なアプリケーションはクラウドのセルフサービスのアプローチによる恩恵を受けることができます。オンプレミスでは一般的な固定のオーバヘッドを削減、あるいは無くすことができます。
- 小規模なアプリケーションからタイムリーなフィードバックを得ることができるので、あなたの期待を修正することができます。
重要でないアプリケーションのクラウドへの移行は良いスタートです。しかし、限界もあります。
- 一般的にクラウドプロバイダーはオンプレミス環境より良いアップタイムとセキュリティを提供します。したがって、重要なワークロードの移行はよりメリットがあるでしょう。
- 単純なアプリケーションの移行から多くのことを学ぶことができますが、これから移行するアプリケーションとはセキュリティ、アップタイム、スケーラビリティに関する要件が異なるかもしれません。完全な移行にかかる労力を過小評価しないように注意してください。
一般的には「つま先を水につける」戦略は「全てが落ち着くまで待て」アプローチに勝ります。
ライフサイクル: 開発と本番 (Lifecycle: Development vs. Production)
有名な象(私のようなベジタリアンにとってはナス)を分割する方法はたくさんあります。ランタイムコンポーネントの分割と異なるアプローチはアプリケーションライフサイクルによる分割です。例えば、規制による制約のため本番環境はオンプレミスのままで、ツール、テスト、ステージング環境をクラウドで実行することができます。
ビルドとテスト環境をクラウドに移行するのは良い考えです。
- ビルドとテスト環境で本物の顧客データを使うことはほとんどありません。データのプライバシーと保存場所に関するほとんどの懸念は当てはまりません。
- 開発、テスト、ビルド環境は本質的に一時的なものです。したがって、クラウドの柔軟性を利用し、必要に応じて構築、削除することによってインフラストラクチャのコストを三倍以上削減できます。一週間で考えると、コアの稼働時間は168時間の三分の一未満になります。機能テスト環境は、使える状態になるまでのji間の速さに応じてより稼働時間が短くなるでしょう。
- 多くのビルドシステムは耐障害性が高いため、プリエンプティブルインスタンスやスポットインスタンスを使うことにより、さらに多くの費用を削減できます。
アーキテクチャはトレードオフの問題であることはご存知でしょう。したがって、次の点に注意してください。
- ソフトウェアのライフサイクルをオンプレミスとクラウドに分割すると、テスト環境と本番環境に違いが発生します。パフォーマンスのボトルネックや本番環境でのみバグが発生する可能性のある微妙な差異を検出できないかもしれない危険があります。
- ビルドツールが生成する成果物のサイズが大きい場合、オンプレミスにデプロイする時に遅延が発生したり、外向きの通信料金が問題になるかもしれません。
このアプローチは本番用のワークロードをクラウドで動かすことが禁じられているが、クラウドをできる限り活用したい開発チームにとって最も一般的な選択肢です。
データ区分: 機密性の高くないものと機密性の高いもの (Data Classification: Non-sensitive vs. Sensitive)
ハイブリッドクラウドにおける計算という側面は比較的単純です。コードを異なる環境に再デプロイするのは簡単ですから。データは違います。データは大体一箇所にあるので、移行、あるいは同期が必要です。計算処理だけを移行し、データをオンプレミスに置いたままにすると、パフォーマンスが大幅に低下するでしょう。つまり、クラウドへの移行を妨げることが多いのはデータです。
データ区分はアプリケーションをクラウドに移行する際の障害となる可能性があるので、機密性の高いデータをオンプレに置いたまま機密性の低いデータだけをクラウドに移行するのは自然な分割方法です。
- 機密性の高いデータはオンプレミスに残り、他のリージョンに複製されないので、データの保存場所に関する一般的な内部基準に準拠できます。
- クラウドからの情報漏洩が発生したとしても被害範囲を限定することができます。
しかしながら、このアプローチは今日のコンピューティング環境に必ずしも当てはまらない前提に基づいています。
- ずる賢い攻撃や低レベルの脆弱性からオンプレミスを守ることは困難な問題になりつつあります。例えば、SpectreやMeltdownのようなCPUレベルの脆弱性はアナウンス前に一部のクラウドプロバイダーによって修正されました。これはオンプレミスでは実現できませんでした。
- 悪意あるデータアクセスや攻撃は必ずしもデータに直接アクセスするわけではありません。しばしば、たくさんの「ホップ」を経由します。クラウドにシステムを持っている場合、機密性の高いデータをオンプレミスに置いてあるからといってデータが安全だとは限りません。例えば、最悪のデータ漏洩の一つであり、最大1億4500万件の顧客のレコードに影響したEquifaxのデータ漏洩ではデータはオンプレミスに保存されていました。
したがって、規制やポリシーの制約に対応するためにこのアプローチから始めることは適切ですが、長期的な戦略として用いる場合には注意が必要です。
データの鮮度: バックアップと稼働中 (Data Freshness: Back-up vs. Operational)
全てのデータが常にアプリケーションによってアクセスされるわけではありません。実際のところ、多くの企業では大部分のデータが「コールド」、つまり滅多にアクセスされません。例えば、過去のレコードやバックアップがそうです。クラウドプロバイダーは滅多にアクセスされないデータ向けの魅力的な選択肢を提供しています。AmazonのGlacierはこのようなユースケースを対象とした最初の製品の一つです。Azure Storage Archive TierやGCP Coldline Cloud Storageのような特別なストレージサービス層を提供しているプロバイダもあります。
データをクラウドにアーカイブすることは道理にかなっています。
- バックアップとリストアは一般的に日常の運用とは別に行います。したがって、アプリケーションの移行や再設計なしに、クラウドを活用することができます。
- 古いアプリケーションにとってデータストレージの費用は運用費全体の中で大きな割合を占める可能性があります。このような場合、いくつかのデータをクラウドに移動する事によりすぐに費用を削減できます。
- アーカイブという目的のためには、普段使っているデータセンターから離れた場所にデータを置くのは良い考えです。
残念ながら、制約もあります。
- データリカバリの費用は高くなるかもしれません。したがって、滅多に必要としないデータだけをクラウドに移行することになるかもしれません。
- バックアップするデータは顧客のデータ、あるいは誰かの所有しているデータを含んでいることが多いため、暗号化するか、他の方法で保護する必要があります。これによって、データの重複を取り除くような最適化ができない可能性があります。
しかしながら、クラウドによるバックアップは企業にとってクラウドの恩恵をすぐに受けることのできる良い方法です。
稼働状況: 災害時と通常時 (Operational State: Disaster vs. BAU)
システムの稼働状況によってワークロードを分割することもできます。わかりやすい稼働状況の分類は、物事が順調か(「通常」)、あるいは主なコンピュータリソースが稼働していないか(「災害」)です。システムをオンプレミスで動かすことを望んでいる、あるいは規制機関が望んでいるとしても、オンプレミス上のシステムが利用できなくなった場合に、全く利用できないより、クラウド上のシステムを利用できるほうが良いかもしれません。
同じコードを両方の環境で動かす、ただし異なる状況ににおいてという点で、このワークロード分割アプローチは他のアプローチと大きく異なっています。
- 通常時にはクラウド上でワークロードは稼働しません
- クラウドの利用は一時的なので、クラウドの柔軟な課金アプローチを活用できます
しかしながら、物事はそれほど単純ではありません。
- 緊急時にクラウドで運用するためには、クラウドからアクセスでき、想定停止シナリオの影響を受けない場所にデータを同期する必要があります。多くの場合、そのような場所はクラウドでしょう。そうなると、d尾のような状況でもシステムをクラウドで運用することを検討したくなるでしょう。
- 緊急事態のためだけにクラウドを使うと、多くの場合クラウドで運用する利点が失われます。
つまり、このアプローチは大量のデータを必要としない計算タスクに最も適しています。例えば、メインサイトが利用できない時も顧客が注文可能なeコマースサイトです。これは、メインシステムが復旧するまで、(公開)カタログから選び注文を保存することによって可能です。可愛いらしい404、あるいは500ページよりは良いでしょう。
ワークロードの需要: バーストと通常 (Workload Demand: Burst vs Normal Operations)
大事なことを言い忘れていましたが、ひどい緊急事態でなくとも、通常時はオンプレミスで実行しつつ、時々ワークロードをクラウドに移行することはできます。かつて頻繁に引用されたアプローチはバーストをクラウドで実行する事です。つまり、オンプレミスの処理能力は固定で、それ以上の処理能力が必要になったら一時的にクラウドに拡張します。
今までと同様にこの選択肢にも利点があります。
- 短時間のバーストは比較的安価なので、クラウドの柔軟な課金モデルはこのアプローチに最適です。
- ほとんどの時間はオンプレミスだけで運用できます。
しかしながら、人々がこの選択肢についてもはや話さないのには理由があります。
- 前と同じ話ですが、クラウドインスタンスからデータにアクセスする必要があります。つまり、クラウドにデータを複製することになりますが、これは一番避けたかったことのはずです。あるいは、クラウドインスタンスからオンプレミス上のデータを操作する必要があります。これは大きな遅延という対価を払う事になるでしょう。
- 高負荷の状態でオンプレミスとクラウド上で同時に実行できるアプリケーションアーキテクチャが必要です。そしてそれは簡単ではありません。
この選択肢はシミュレーションのような計算中心のワークロードに最適です。また、クラウド上で急いで機械的に何かをするような一回限りの計算タスクにも向いています。例えば、このアプローチはニューヨークタイムズが600万枚の写真をデジタル化したり、円周率を31兆桁まで計算したりするのに最適でした。
実践してみよう
ほとんどの企業はハイブリッドクラウドを避けることができません。したがって、ハイブリッドクラウドを最大限に活用するの良い計画が必要です。ワークロードをクラウドとオンプレミス環境に分割するための選択肢は多いため、これらの選択肢をカタログ化する事により、考え抜かれ、明確に話し合われた決定が可能となります。また、「一つのサイズで全てに対応できる」と宣言することを避けることができます。これらはより良いアーキテクトであるための考え方です。
楽しい分割と移行を!
ps: もし、まだ知らないのであれば、Simon Wardleyのハイブリッドクラウドに対する面白い見解を読んでみてください。
その他のクラウド戦略に関する見解
- ハイブリッドマルチクラウド: あるエレベーターアーキテクトの見解
- 自分達で構築していないものを動かすな
- 「実行のための変動費用」が増えるのは良いことかもしれません [Linkedin]
- クラウドコンピューティングはインフラストラクチャのトピックではない [Linkedin]
注: この記事の執筆や関連するクラウド移行によって象に被害がなかったことを証明します。